# 2. 反编译通用架构与示例
这里先介绍反编译器的大体工作流程,有哪些的关键模块,以及这一系列文章会讨论的关键点。
## 啥是反编译器,啥是逆向软件
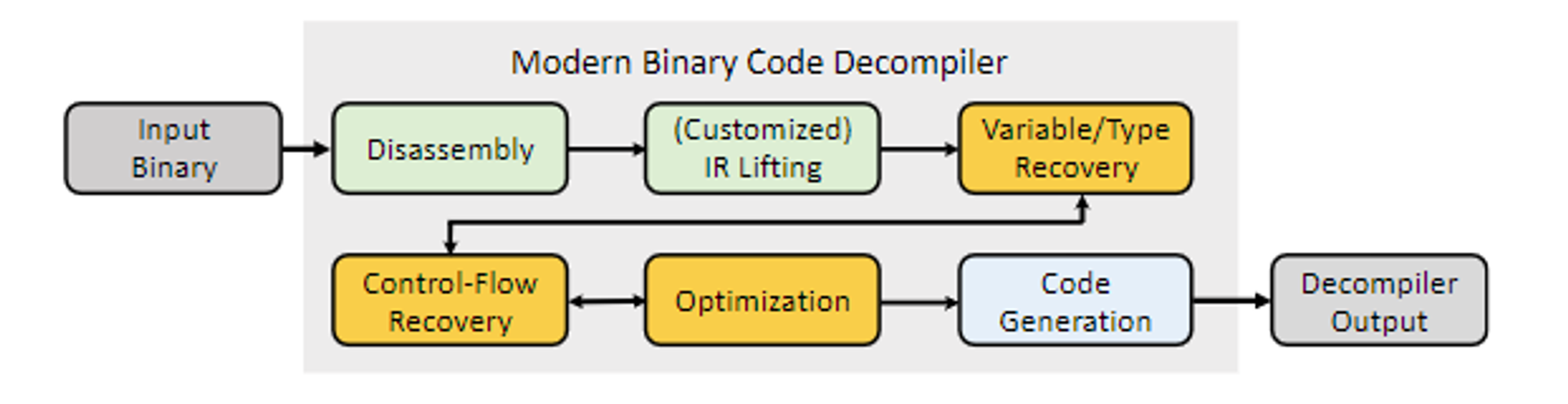 如上图所示,是典型的学术形的反编译”算法”流程。流程描述了有哪些步骤,每一步在做什么。
而我更想讨论的逆向软件,相比于反编译器,逆向软件是一套完整的系统。
一套完整的系统还必须说明
* 系统的架构,在哪一部分做哪些事。通用流程告诉你“今天晚上吃麦当劳”,但是我告诉你“麦当劳的甜筒领券今天免费”。
* 关键点在于:不同逆向软件实现的异同点。为什么他们“这样实现”或者“不这样实现”
* 对于实际的算法实现中,准确率与效率的取舍,毕竟世界上很难有两全其美的东西。
* 关于二进制中各种特化的实现;学术界往往提出各种通用的解决方案,但是特化的方案,反而是正真反编译器最常用的那个。
* 反编译器中的插件扩展能力。
## 反编译通用流程
以下为来自某个论文的通用反编译器图
如上图所示,是典型的学术形的反编译”算法”流程。流程描述了有哪些步骤,每一步在做什么。
而我更想讨论的逆向软件,相比于反编译器,逆向软件是一套完整的系统。
一套完整的系统还必须说明
* 系统的架构,在哪一部分做哪些事。通用流程告诉你“今天晚上吃麦当劳”,但是我告诉你“麦当劳的甜筒领券今天免费”。
* 关键点在于:不同逆向软件实现的异同点。为什么他们“这样实现”或者“不这样实现”
* 对于实际的算法实现中,准确率与效率的取舍,毕竟世界上很难有两全其美的东西。
* 关于二进制中各种特化的实现;学术界往往提出各种通用的解决方案,但是特化的方案,反而是正真反编译器最常用的那个。
* 反编译器中的插件扩展能力。
## 反编译通用流程
以下为来自某个论文的通用反编译器图
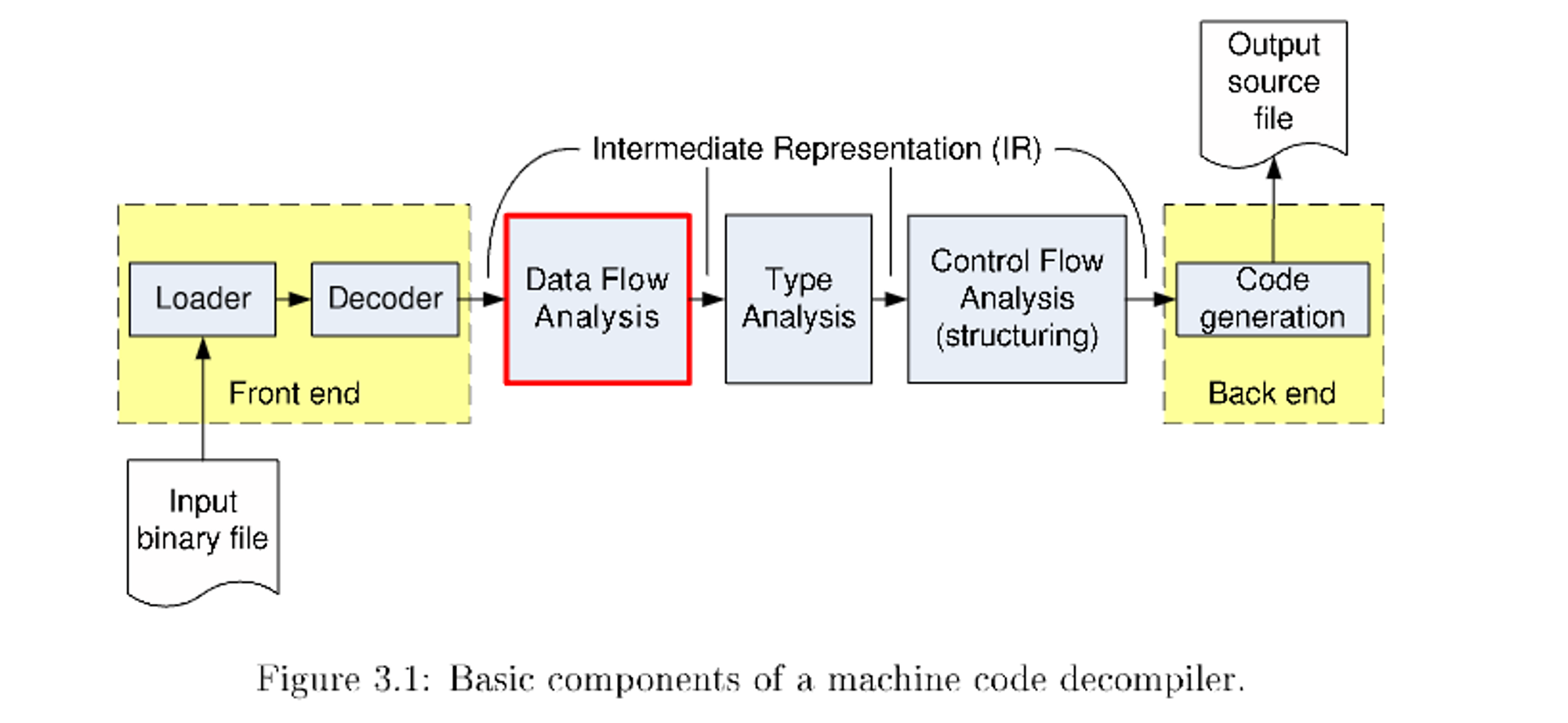 注:这个系列不会说明将二进制文件解析的实现细节,有需要的可以看Angr-CLE等工具的相关文档。主要的内容是对中后端技术的讨论。
### **架构概述:**
其实反编译和编译器很像,当前主流的反编译器也使用了很多的编译器的技术与算法。
在整体结构上也区分为:前端、中端、后端;
但是相比与编译器他的结构是反过来的,即,反编译器的前端处理的是二进制与机器码,后端目标是生成人类可读甚至直接可编译的源代码。
这个系列的文章,主要内容集中在中端,中端优化的目标是提取汇编与程序结构中隐含的信息还原成人类熟悉的高层次结构。
### **前端:**
**1、解析二进制文件结构**
二进制的格式有很多种,各种各样的格式也很复杂,各种压缩,各种偏移计算,就像上面说的那样这篇文章不会详细讨论这部分繁杂的内容
**2、解析机器码,生成IR或者汇编(反汇编)**
反汇编,即解析机器码的的主要几个问题:
* 怎么解决数据与代码逻辑混合的场景?
* 怎么处理间接跳转与间接调用,有哪些特殊情况。
* 从哪里开始反编译,如何从数据中找到所有函数的入口点?
* 为什么要使用中间语言,主流的中间语言方案
关于IR(中间语言)的生成,大部分的反编译是直接将机器码转为IR的;(并不是先转换为汇编,再把汇编转换为IR)
还有关于IR的设计话题,这个话题太大了,有大佬说过”中间语言的设计相比于科学更像是艺术”;
截至目前(2023年)世界上的IR也太多太多了,我已经做不到将他们的各个设计总结出来,因此这部分的内容只能移到最后,去讨论现在的反编译工具比如IDA/GHIDRA/angr 所使用的IR。
### **中端:**
**1、数据流分析(Data-Flow-Analysis)+规则分析**
这部分是反编译器中最复杂,内容最多的部分,涉及了各种丰富多彩的话题。比如:
* 识别全局指针
* CFG与SSA(low-level variables)的构建
* 插入phi并处理关联
* 死代码消除
* 常量传播
* 拷贝传播
* 规则匹配类型优化
* 函数调用的返回值与参数与归一化
* 栈平衡与栈变量识别
* 还原高层次变量
数据流分析的主要目的,一个是将相对低级的中间语言中的高级语意提取出来,一个是将高级语义进行各种特化规则的转化。
**2、类型还原(Type-infer)**
现在常用的反编译器的核心设计时没有跨函数全局程序分析的场景,20年前也没有go或者rust这种复杂的东西,因此,类型系统的还原还处于一个比较初阶的阶段。类型还原的主要话题:
* 类型还原系统的设计理念
* 基于格理论的类型还原技术
* 中间语言与类型约束
* 结构体的识别
* 数组的识别
* 类型传播
* 跨函数的全局变量类型恢复
**3、控制流还原(也被称为结构分析struct)**
将CFG还原成由 if-else while for 组成的结构(尽量不包含goto)。
并将各种条件的变量进行合并,规约成适合人类阅读的模式。这里主要的困难在于如何解决控制流图中“不可规约结构”或者叫做”非标准化结构”的问题
* 基于区间分析/控制分析的控制流还原技术
* 真实逆向软件中的控制流恢复方案
* 如何解决“图不可规约”问题
* 条件语句归一化与条件合并
* 约束与条件简化
### **后端:**
**代码生成:**
将上述的各种还原后的东西最终组合,生成可读性高的代码
注意,代码并不是越简略可读性就越高,合理的加入中间变量与中间表达式更加合适。
后面在优化技术中会再次讨论这部分内容。
## 如何评判一个逆向软件的好坏?
1、支持的架构、ISA、指令集:虽然历史上的很多指令集现在不太能见得到(比如PPC之类的),但是一个成熟的工具至少要支持常见的ARM、x86\_64、MIPS架构
2、反编译效率:至少10M的文件要在半个小时能跑完吧,我还记得以前把带符号的kernel放到Ghidra里(100M+),第二天来了它还在跑呢(叹气)。
3、生成代码的准确度:简单的来说就是正确性和可读性,包括控制流结构、类型信息、变量信息还原等等,当然,前提是语义绝不能出错。
4、代码可读性:当前反编译生成的代码可读性还存在很多问题了;并且当前主流的反编译工具的设计往往在20年前,希望在下个十年能出现支持高级语言以及更高抽象语义的反编译器。
## 示例:一个简单程序的反编译流程示例
注意,这个流程中我简化或者抽象了大量的内容,其实可以不看,每个点后面会慢慢讲。
示例源代码:
```c
#include
int main() {
int x, y;
scanf("%d,%d", &x, &y);
if (x > 0) {
y = y / 3;
}
printf("y = %d", y);
return 0;
}
```
现在使用clang -O3将它编译,然后进行反编译。(使用clang,是因为clang生成的代码废话少一点)
我跳过了二进制格式识别与汇编转换的流程,毕竟前者不是我们的重点,后者在这里讨论没有啥意义
直接看代码段的汇编:
```jsx
..text:001150 ; int main()
.text:001150 var_10 = dword ptr -10h
.text:001150 var_C = dword ptr -0Ch
.text:001150 push rbx
.text:001151 sub rsp, 10h
.text:001155 lea rdi, 0x2004 ; "%d,%d"
.text:00115C xor ebx, ebx
.text:00115E lea rsi, [rsp+18h+var_10]
.text:001163 lea rdx, [rsp+18h+var_C]
.text:001168 xor eax, eax
.text:00116A call ___isoc99_scanf
.text:00116F cmp [rsp+18h+var_10], 0
.text:001174 jz short loc_118B
.text:001176 mov eax, [rsp+18h+var_C]
.text:00117A mov ebx, 0AAAAAAABh
.text:00117F imul rbx, rax
.text:001183 shr rbx, 21h
.text:001187 mov [rsp+18h+var_10], ebx
.text:00118B loc_118B: ; CODE XREF: main+24
.text:00118B lea rdi, 0x200A ; "y = %d"
.text:001192 mov esi, ebx
.text:001194 xor eax, eax
.text:001196 call _printf
.text:00119B xor eax, eax
.text:00119D add rsp, 10h
.text:0011A1 pop rbx
.text:0011A2 retn
```
* **第一步**,将二进制转化为中间语言,但是现有的中间语言设计出来就没有适合人类阅读的,我只能再这里现场造一个“伪语言”临时用一下。当然,现场造的好处是我默认进行了“死代码消除”、“栈变量识别”、“条件跳转规约”这些步骤
```jsx
..text:001150 ; int main()
.text:001150 var_10 = dword ptr -10h
.text:001150 var_C = dword ptr -0Ch
.text:001150 push rbx
[rsp] = rbx
rsp = rsp - 0x08
.text:001151 sub rsp, 10h
rsp = rsp - 0x10
.text:001155 lea rdi, 0x2004 ; "%d,%d"
rdi = 0x2004
.text:00115C xor ebx, ebx
ebx = 0
.text:00115E lea rsi, [rsp+18h+var_10]
rsi = addr stack_var_0x10
.text:001163 lea rdx, [rsp+18h+var_C]
rdx = addr stack_var_0x0C
.text:001168 xor eax, eax
eax = 0
.text:00116A call ___isoc99_scanf
scanf()
.text:00116F cmp [rsp+18h+var_10], 0
.text:001174 jz short loc_118B
if stack_var_0x10 < 0;
goto loc_118B
.text:001176 mov eax, [rsp+18h+var_C]
eax = stack_var_0x0C
.text:00117A mov ebx, 0AAAAAAABh
ebx = 0xAAAAAAAB
.text:00117F imul rbx, rax
rbx = rbx * rax
.text:001183 shr rbx, 21h
rbx = rbx >> 21
.text:001187 mov [rsp+18h+var_10], ebx
stack_var_0x10 = ebx
.text:00118B loc_118B: ; CODE XREF: main+24
.text:00118B lea rdi, 0x200A ; "y = %d"
rdi = 0x200A
.text:001192 mov esi, ebx
esi = ebx
.text:001194 xor eax, eax
eax = 0
.text:001196 call _printf
printf()
.text:00119B xor eax, eax
eax = 0
.text:00119D add rsp, 10h
rsp = rsp + 0x10
.text:0011A1 pop rbx
rbx = [rsp]
.text:0011A2 retn
end-function
```
我们翻译好的东西放到一起
```jsx
int main() {
[rsp] = rbx
rsp = rsp - 0x08
rsp = rsp - 0x10
rdi = 0x2004
ebx = 0
rsi = addr stack_var_0x10
rdx = addr stack_var_0x0C
eax_1 = 0
scanf()
if stack_var_0x10 <= 0;
goto loc_118B
{
eax = stack_var_0x0C
ebx = 0xAAAAAAAB
rbx = rbx * rax
rbx = rbx >> 0x21
stack_var_0x10 = ebx
}
loc_118B:
rdi = 0x200A
esi = ebx
eax = 0
printf()
eax = 0
rsp = rsp + 0x10
rbx = [rsp]
return
}
```
第二步 将上面的中间结果,转换为SSA模式,插入phi函数
```jsx
int main() {
[rsp0] = rbx_0
rsp_1 = rsp_0 - 0x08
rsp_2 = rsp_1 - 0x10
rdi_1 = 0x2004
ebx_1 = 0
rsi_1 = rsp_2+0xC
rdx_1 = rsp_2+0x10
eax_1 = 0
scanf()
if stack_var_0x10 <= 0;
goto loc_118B
{
eax_2 = rsp_2+0xC
ebx_2 = 0xAAAAAAAB
rbx_1 = zext(ebx_2)
rbx_2 = rbx_1 * rax
rbx_3 = rbx_2 >> 0x21
[rsp_2+0x10] = ebx_2
}
rbx_4 = phi(rbx_3, rbx_1)
eax_3 = phi(eax_1, eax_2)
loc_118B:
rdi_2 = 0x200A
ebx_3 = zext(rbx_4)
esi_1 = ebx_3
eax_4 = 0
printf()
eax_5 = 0
rsp_3 = rsp_2 + 0x10
rbx_6 = [rsp_3]
return
}
```
第三步 中间优化:消除死代码,识别函数调用参数与返回值、传播常量、平衡出入栈、规则优化。
* 消除没有用的变量与指令
* 通过调用约定来识别子函数调用的参数以及返回值
* 传播常量变量,识别全局变量引用
* 平衡这个函数入口与出口的栈操作,计算栈操作时的偏移信息,将栈偏移同步到栈变量中
* 使用规则进行优化,这里能匹配到“除法优化”规则:(2\*\*0x21) // (0xAAAAAAAB-1) ==3,即可以知道 (X\*0xAAAAAAAB)>>0x21 算法本质上是源码中除以 X/3 被优化后的结果
```jsx
int main() {
scanf("%d,%d", (rsp_2+0x10), (rsp_2+0xC))
if [rsp_2+0x10] <= 0;
goto loc_118B
{
eax_2 = rsp_2+0xC
rbx_1 = zext(ebx_2)
rbx_3 = rbx_1 /3
[rsp_2+0x10] = ebx_2
}
rbx_4 = phi(rbx_3, rbx_1)
eax_3 = phi(eax_1, eax_2)
loc_118B:
ebx_3 = zext(rbx_4)
printf("y = %d", ebx_3)
return 0
}
```
第四步,变量还原
基于phi函数与copy语句,以及栈变量的标记,将SSA形式的中间语言转换为实际的“高阶变量”
```jsx
int main() {
var stack_0x10
var stack_0x0C
var tmp_RBX
scanf("%d,%d", &stack_0x10, &stack_0x0C)
if stack_0x10 <= 0;
goto loc_118B
{
tmp_RBX = stack_0x10
tmp_RBX= tmp_RBX/3
stack_0x10 = tmp_RBX
}
loc_118B:
printf("y = %d", tmp_RBX)
return 0
}
```
第五步,类型信息
* 对于大量的计算的中间语言,它本身带有类型信息,中间语言生成时就已经完成这一步了
* 将中间语言的类型信息同步到变量中去,基于约束求解与格理论,推测类型信息
```jsx
int main() {
var stack_0x10 -> int
var stack_0x0C -> int
var tmp_RBX
scanf("%d,%d", &stack_0x10, &stack_0x0C) : int, int
if stack_0x10 <= 0;
goto loc_118B
{
tmp_RBX = stack_0x10 :
tmp_RBX= tmp_RBX/3 : int
stack_0x10 = tmp_RBX
}
loc_118B:
printf("y = %d", tmp_RBX) : int
return 0
}
```
第六步,还原控制流,归一化控制流格式
```jsx
int main() {
var stack_0x10 -> int
var stack_0x0C -> int
var tmp_RBX
scanf("%d,%d", &stack_0x10, &stack_0x0C) : int, int
if stack_0x10 > 0;
{
tmp_RBX = stack_0x10 :
tmp_RBX= tmp_RBX/3 : int
stack_0x10 = tmp_RBX
}
printf("y = %d", tmp_RBX) : int
return 0
}
```
第七步,生成最终的代码(使用IDA作为参考)
```jsx
int __cdecl main(int argc, const char **argv, const char **envp)
{
unsigned int v3; // ebx
unsigned int v5; // [rsp+8h] [rbp-10h] BYREF
unsigned int v6; // [rsp+Ch] [rbp-Ch] BYREF
v3 = 0;
__isoc99_scanf("%d,%d", &v5, &v6);
if ( v5 )
{
v3 = v6 / 3;
}
printf("y = %d", v3);
return 0;
}
```
以上,就是这一章所有的内容了。
注:这个系列不会说明将二进制文件解析的实现细节,有需要的可以看Angr-CLE等工具的相关文档。主要的内容是对中后端技术的讨论。
### **架构概述:**
其实反编译和编译器很像,当前主流的反编译器也使用了很多的编译器的技术与算法。
在整体结构上也区分为:前端、中端、后端;
但是相比与编译器他的结构是反过来的,即,反编译器的前端处理的是二进制与机器码,后端目标是生成人类可读甚至直接可编译的源代码。
这个系列的文章,主要内容集中在中端,中端优化的目标是提取汇编与程序结构中隐含的信息还原成人类熟悉的高层次结构。
### **前端:**
**1、解析二进制文件结构**
二进制的格式有很多种,各种各样的格式也很复杂,各种压缩,各种偏移计算,就像上面说的那样这篇文章不会详细讨论这部分繁杂的内容
**2、解析机器码,生成IR或者汇编(反汇编)**
反汇编,即解析机器码的的主要几个问题:
* 怎么解决数据与代码逻辑混合的场景?
* 怎么处理间接跳转与间接调用,有哪些特殊情况。
* 从哪里开始反编译,如何从数据中找到所有函数的入口点?
* 为什么要使用中间语言,主流的中间语言方案
关于IR(中间语言)的生成,大部分的反编译是直接将机器码转为IR的;(并不是先转换为汇编,再把汇编转换为IR)
还有关于IR的设计话题,这个话题太大了,有大佬说过”中间语言的设计相比于科学更像是艺术”;
截至目前(2023年)世界上的IR也太多太多了,我已经做不到将他们的各个设计总结出来,因此这部分的内容只能移到最后,去讨论现在的反编译工具比如IDA/GHIDRA/angr 所使用的IR。
### **中端:**
**1、数据流分析(Data-Flow-Analysis)+规则分析**
这部分是反编译器中最复杂,内容最多的部分,涉及了各种丰富多彩的话题。比如:
* 识别全局指针
* CFG与SSA(low-level variables)的构建
* 插入phi并处理关联
* 死代码消除
* 常量传播
* 拷贝传播
* 规则匹配类型优化
* 函数调用的返回值与参数与归一化
* 栈平衡与栈变量识别
* 还原高层次变量
数据流分析的主要目的,一个是将相对低级的中间语言中的高级语意提取出来,一个是将高级语义进行各种特化规则的转化。
**2、类型还原(Type-infer)**
现在常用的反编译器的核心设计时没有跨函数全局程序分析的场景,20年前也没有go或者rust这种复杂的东西,因此,类型系统的还原还处于一个比较初阶的阶段。类型还原的主要话题:
* 类型还原系统的设计理念
* 基于格理论的类型还原技术
* 中间语言与类型约束
* 结构体的识别
* 数组的识别
* 类型传播
* 跨函数的全局变量类型恢复
**3、控制流还原(也被称为结构分析struct)**
将CFG还原成由 if-else while for 组成的结构(尽量不包含goto)。
并将各种条件的变量进行合并,规约成适合人类阅读的模式。这里主要的困难在于如何解决控制流图中“不可规约结构”或者叫做”非标准化结构”的问题
* 基于区间分析/控制分析的控制流还原技术
* 真实逆向软件中的控制流恢复方案
* 如何解决“图不可规约”问题
* 条件语句归一化与条件合并
* 约束与条件简化
### **后端:**
**代码生成:**
将上述的各种还原后的东西最终组合,生成可读性高的代码
注意,代码并不是越简略可读性就越高,合理的加入中间变量与中间表达式更加合适。
后面在优化技术中会再次讨论这部分内容。
## 如何评判一个逆向软件的好坏?
1、支持的架构、ISA、指令集:虽然历史上的很多指令集现在不太能见得到(比如PPC之类的),但是一个成熟的工具至少要支持常见的ARM、x86\_64、MIPS架构
2、反编译效率:至少10M的文件要在半个小时能跑完吧,我还记得以前把带符号的kernel放到Ghidra里(100M+),第二天来了它还在跑呢(叹气)。
3、生成代码的准确度:简单的来说就是正确性和可读性,包括控制流结构、类型信息、变量信息还原等等,当然,前提是语义绝不能出错。
4、代码可读性:当前反编译生成的代码可读性还存在很多问题了;并且当前主流的反编译工具的设计往往在20年前,希望在下个十年能出现支持高级语言以及更高抽象语义的反编译器。
## 示例:一个简单程序的反编译流程示例
注意,这个流程中我简化或者抽象了大量的内容,其实可以不看,每个点后面会慢慢讲。
示例源代码:
```c
#include
int main() {
int x, y;
scanf("%d,%d", &x, &y);
if (x > 0) {
y = y / 3;
}
printf("y = %d", y);
return 0;
}
```
现在使用clang -O3将它编译,然后进行反编译。(使用clang,是因为clang生成的代码废话少一点)
我跳过了二进制格式识别与汇编转换的流程,毕竟前者不是我们的重点,后者在这里讨论没有啥意义
直接看代码段的汇编:
```jsx
..text:001150 ; int main()
.text:001150 var_10 = dword ptr -10h
.text:001150 var_C = dword ptr -0Ch
.text:001150 push rbx
.text:001151 sub rsp, 10h
.text:001155 lea rdi, 0x2004 ; "%d,%d"
.text:00115C xor ebx, ebx
.text:00115E lea rsi, [rsp+18h+var_10]
.text:001163 lea rdx, [rsp+18h+var_C]
.text:001168 xor eax, eax
.text:00116A call ___isoc99_scanf
.text:00116F cmp [rsp+18h+var_10], 0
.text:001174 jz short loc_118B
.text:001176 mov eax, [rsp+18h+var_C]
.text:00117A mov ebx, 0AAAAAAABh
.text:00117F imul rbx, rax
.text:001183 shr rbx, 21h
.text:001187 mov [rsp+18h+var_10], ebx
.text:00118B loc_118B: ; CODE XREF: main+24
.text:00118B lea rdi, 0x200A ; "y = %d"
.text:001192 mov esi, ebx
.text:001194 xor eax, eax
.text:001196 call _printf
.text:00119B xor eax, eax
.text:00119D add rsp, 10h
.text:0011A1 pop rbx
.text:0011A2 retn
```
* **第一步**,将二进制转化为中间语言,但是现有的中间语言设计出来就没有适合人类阅读的,我只能再这里现场造一个“伪语言”临时用一下。当然,现场造的好处是我默认进行了“死代码消除”、“栈变量识别”、“条件跳转规约”这些步骤
```jsx
..text:001150 ; int main()
.text:001150 var_10 = dword ptr -10h
.text:001150 var_C = dword ptr -0Ch
.text:001150 push rbx
[rsp] = rbx
rsp = rsp - 0x08
.text:001151 sub rsp, 10h
rsp = rsp - 0x10
.text:001155 lea rdi, 0x2004 ; "%d,%d"
rdi = 0x2004
.text:00115C xor ebx, ebx
ebx = 0
.text:00115E lea rsi, [rsp+18h+var_10]
rsi = addr stack_var_0x10
.text:001163 lea rdx, [rsp+18h+var_C]
rdx = addr stack_var_0x0C
.text:001168 xor eax, eax
eax = 0
.text:00116A call ___isoc99_scanf
scanf()
.text:00116F cmp [rsp+18h+var_10], 0
.text:001174 jz short loc_118B
if stack_var_0x10 < 0;
goto loc_118B
.text:001176 mov eax, [rsp+18h+var_C]
eax = stack_var_0x0C
.text:00117A mov ebx, 0AAAAAAABh
ebx = 0xAAAAAAAB
.text:00117F imul rbx, rax
rbx = rbx * rax
.text:001183 shr rbx, 21h
rbx = rbx >> 21
.text:001187 mov [rsp+18h+var_10], ebx
stack_var_0x10 = ebx
.text:00118B loc_118B: ; CODE XREF: main+24
.text:00118B lea rdi, 0x200A ; "y = %d"
rdi = 0x200A
.text:001192 mov esi, ebx
esi = ebx
.text:001194 xor eax, eax
eax = 0
.text:001196 call _printf
printf()
.text:00119B xor eax, eax
eax = 0
.text:00119D add rsp, 10h
rsp = rsp + 0x10
.text:0011A1 pop rbx
rbx = [rsp]
.text:0011A2 retn
end-function
```
我们翻译好的东西放到一起
```jsx
int main() {
[rsp] = rbx
rsp = rsp - 0x08
rsp = rsp - 0x10
rdi = 0x2004
ebx = 0
rsi = addr stack_var_0x10
rdx = addr stack_var_0x0C
eax_1 = 0
scanf()
if stack_var_0x10 <= 0;
goto loc_118B
{
eax = stack_var_0x0C
ebx = 0xAAAAAAAB
rbx = rbx * rax
rbx = rbx >> 0x21
stack_var_0x10 = ebx
}
loc_118B:
rdi = 0x200A
esi = ebx
eax = 0
printf()
eax = 0
rsp = rsp + 0x10
rbx = [rsp]
return
}
```
第二步 将上面的中间结果,转换为SSA模式,插入phi函数
```jsx
int main() {
[rsp0] = rbx_0
rsp_1 = rsp_0 - 0x08
rsp_2 = rsp_1 - 0x10
rdi_1 = 0x2004
ebx_1 = 0
rsi_1 = rsp_2+0xC
rdx_1 = rsp_2+0x10
eax_1 = 0
scanf()
if stack_var_0x10 <= 0;
goto loc_118B
{
eax_2 = rsp_2+0xC
ebx_2 = 0xAAAAAAAB
rbx_1 = zext(ebx_2)
rbx_2 = rbx_1 * rax
rbx_3 = rbx_2 >> 0x21
[rsp_2+0x10] = ebx_2
}
rbx_4 = phi(rbx_3, rbx_1)
eax_3 = phi(eax_1, eax_2)
loc_118B:
rdi_2 = 0x200A
ebx_3 = zext(rbx_4)
esi_1 = ebx_3
eax_4 = 0
printf()
eax_5 = 0
rsp_3 = rsp_2 + 0x10
rbx_6 = [rsp_3]
return
}
```
第三步 中间优化:消除死代码,识别函数调用参数与返回值、传播常量、平衡出入栈、规则优化。
* 消除没有用的变量与指令
* 通过调用约定来识别子函数调用的参数以及返回值
* 传播常量变量,识别全局变量引用
* 平衡这个函数入口与出口的栈操作,计算栈操作时的偏移信息,将栈偏移同步到栈变量中
* 使用规则进行优化,这里能匹配到“除法优化”规则:(2\*\*0x21) // (0xAAAAAAAB-1) ==3,即可以知道 (X\*0xAAAAAAAB)>>0x21 算法本质上是源码中除以 X/3 被优化后的结果
```jsx
int main() {
scanf("%d,%d", (rsp_2+0x10), (rsp_2+0xC))
if [rsp_2+0x10] <= 0;
goto loc_118B
{
eax_2 = rsp_2+0xC
rbx_1 = zext(ebx_2)
rbx_3 = rbx_1 /3
[rsp_2+0x10] = ebx_2
}
rbx_4 = phi(rbx_3, rbx_1)
eax_3 = phi(eax_1, eax_2)
loc_118B:
ebx_3 = zext(rbx_4)
printf("y = %d", ebx_3)
return 0
}
```
第四步,变量还原
基于phi函数与copy语句,以及栈变量的标记,将SSA形式的中间语言转换为实际的“高阶变量”
```jsx
int main() {
var stack_0x10
var stack_0x0C
var tmp_RBX
scanf("%d,%d", &stack_0x10, &stack_0x0C)
if stack_0x10 <= 0;
goto loc_118B
{
tmp_RBX = stack_0x10
tmp_RBX= tmp_RBX/3
stack_0x10 = tmp_RBX
}
loc_118B:
printf("y = %d", tmp_RBX)
return 0
}
```
第五步,类型信息
* 对于大量的计算的中间语言,它本身带有类型信息,中间语言生成时就已经完成这一步了
* 将中间语言的类型信息同步到变量中去,基于约束求解与格理论,推测类型信息
```jsx
int main() {
var stack_0x10 -> int
var stack_0x0C -> int
var tmp_RBX
scanf("%d,%d", &stack_0x10, &stack_0x0C) : int, int
if stack_0x10 <= 0;
goto loc_118B
{
tmp_RBX = stack_0x10 :
tmp_RBX= tmp_RBX/3 : int
stack_0x10 = tmp_RBX
}
loc_118B:
printf("y = %d", tmp_RBX) : int
return 0
}
```
第六步,还原控制流,归一化控制流格式
```jsx
int main() {
var stack_0x10 -> int
var stack_0x0C -> int
var tmp_RBX
scanf("%d,%d", &stack_0x10, &stack_0x0C) : int, int
if stack_0x10 > 0;
{
tmp_RBX = stack_0x10 :
tmp_RBX= tmp_RBX/3 : int
stack_0x10 = tmp_RBX
}
printf("y = %d", tmp_RBX) : int
return 0
}
```
第七步,生成最终的代码(使用IDA作为参考)
```jsx
int __cdecl main(int argc, const char **argv, const char **envp)
{
unsigned int v3; // ebx
unsigned int v5; // [rsp+8h] [rbp-10h] BYREF
unsigned int v6; // [rsp+Ch] [rbp-Ch] BYREF
v3 = 0;
__isoc99_scanf("%d,%d", &v5, &v6);
if ( v5 )
{
v3 = v6 / 3;
}
printf("y = %d", v3);
return 0;
}
```
以上,就是这一章所有的内容了。